Participa con tu nota. Contacto: daniela_ldl@ieee.org.ar
Red Internacional de Desarrollo y Producción de Videojuegos REDINDVJ
ORATORIO INTERNACIONAL en videojuegos: Una investigación sobre sistemas inteligentes que aprenden a jugar solitos
Como parte de la actividad de la REDINDVJ los profesionales de la red han analizado y explicado un trabajo de investigación de punta sobre sistemas inteligentes que aprenden a jugar automáticamente distintos tipos de videojuegos.
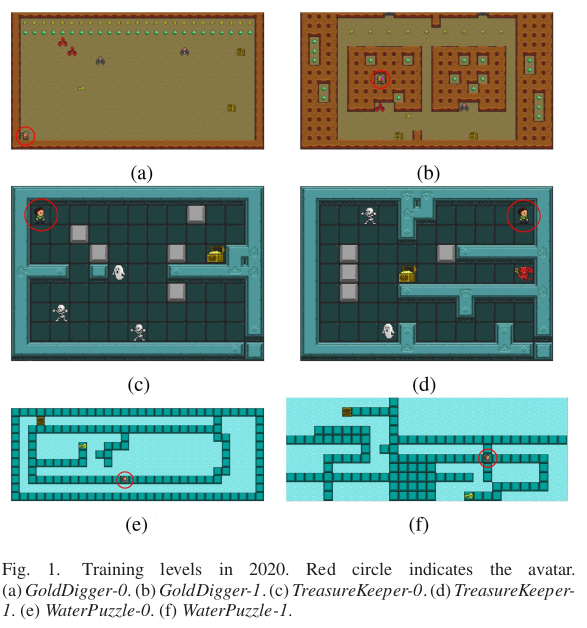
Foto original de Reinforcement Learning With Dual-Observation
for General Video Game Playing (Hu et al.)
Solo se puede divulgar la ciencia de punta involucrando a la comunidad en el análisis de los trabajos publicados en revistas de prestigio internacional. En el área de videojuegos latinoamericana existe el inconveniente de que los científicos no suele escribir en español sino en inglés. Pero los miembros de la Red Internacional de Desarrollo y Producción de Videojuegos (REDINDVJ), formada por especialistas de México, Colombia, Chile y Argentina, realiza desde hace mas de un año actividades para la instalación de temáticas de punta. A su vez sus integrantes han fundado una fuerza de trabajo mancomunada del IEEE, el instituto referente a nivel mundial para la ciencia y tecnología desde hace más de 100 años.
Esa fuerza de trabajo, con objetivos claramente centrados en el desarrollo latino de temáticas en videojuegos y ludificación, es conocida como IEEE GRE Task Force. El día 9 de mayo pasado han organizado un evento denominado ORATORIO, donde varios profesionales explicaron y analizaron un trabajo que explica una técnica innovadora para que un sistema inteligente extienda sus capacidades de jugar cualquier tipo de videojuego de manera ‘óptima’.
Entre las ventajas de un sistema con estas habilidades está la posibilidad de verificar las bondades de un videojuego de manera sistemática y completa. Dado que este área es relativamente nueva, los científicos explican en su trabajo las dificultades que conlleva el uso de técnicas como el denominado “aprendizaje por refuerzo” para dar esta inteligencia a los sistemas digitales.
A lo largo de varios años, se han dado cuenta que generalizar acciones sobre videojuegos requiere de mucha más inteligencia que lo pensado. Por ello los primeros resultados fueron muy magros y debieron ir perfeccionando el tipo de enseñanza y la cantidad de información que le entregaban a la entidad digital.
Pero la constancia de los científicos ha derivado en resultados que, si bien son bastante iniciales, ya permiten hablar de una plataforma que supera las experiencias pasadas. La arquitectura inicial se ha complicado un poco y tiene mucho de parecido a otros trabajos publicados en el área de deep learning para procesamiento de imágenes.
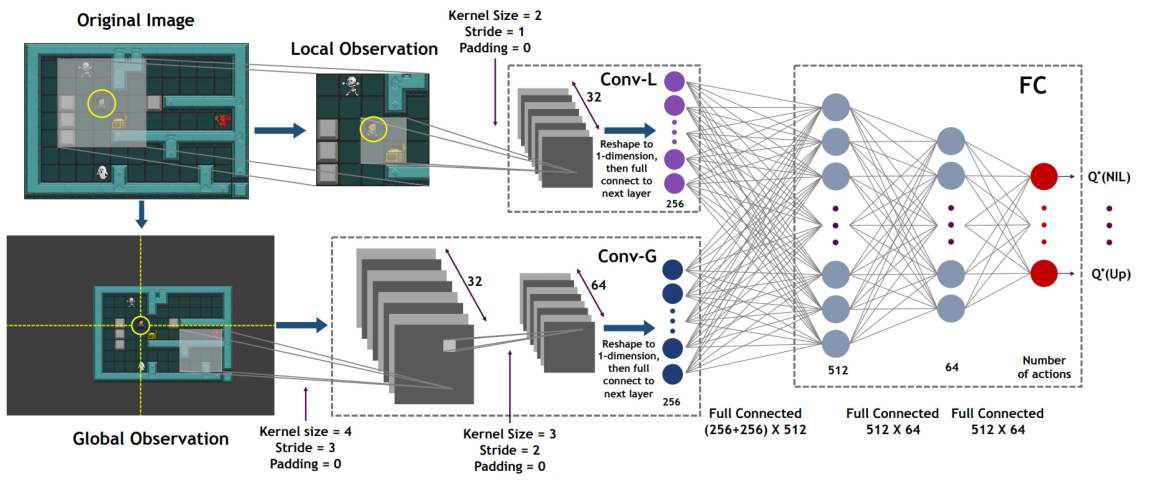
Foto original de Reinforcement Learning With Dual-Observation
for General Video Game Playing (Hu et al.)
Esto no es casual, ya que entre otras lecciones han aprendido que generalizar debe pasar por la imagen de las sucesivas pantallas que el jugador suele atravesar, y por un doble proceso que parece poco evidente: tomar ideas globales de lo que está pasando a cada instante y combinarlas de manera astuta con visiones puntuales de lugares específicos donde se desarrolla la acción dentro de la pantalla. Con un poco de esfuerzo esperamos que en pocos años podamos tener novedades sobre cómo un sistema inteligente puede aprende a jugar en productos que nunca haya visto antes, con una habilidad típica de un gamer. Ahí vendrán otras preguntas que seguramente nos harán pensar en cómo hacer videojuegos que estos jugadores digitales no puedan vencer… ¿o no?
Daniela López De Luise
Academia Nacional de Ciencias de Buenos Aires
Coordinadora Académica CETI
Nota basada en el oratorio REDINDVJ, Sobre el PAPER:
C. Hu et al., «Reinforcement Learning With Dual-Observation for General Video Game Playing,» in IEEE Transactions on Games, vol. 15, no. 2, pp. 202-216, June 2023, doi: 10.1109/TG.2022.3164242.